Why "Live Data Access" Does Not Mean Real-Time Learning
Live data access lets AI retrieve information — not learn from it. Here’s why those are fundamentally different processes.

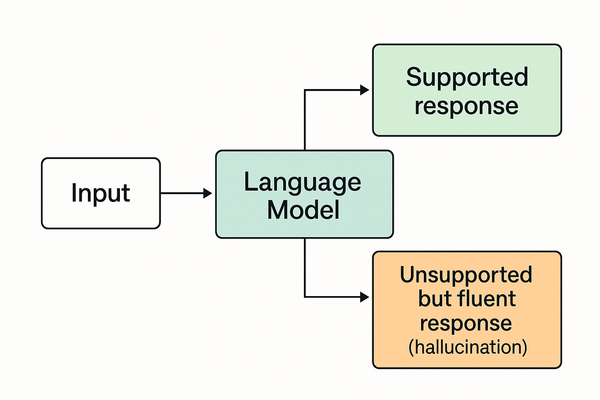
Claims that AI systems “learn in real time” because they can access live data are widespread — and wrong.
This explanation separates data access, inference, and learning, which are often blurred together in public discussion.
Understanding the distinction is essential to evaluating claims about surveillance, memory, and model behaviour.
What “Live Data Access” Actually Means
Some AI systems can retrieve external information at the time of use.
This may include:
- Web search results
- APIs
- Databases
- Tools connected to real-time feeds
The model can read this information and use it to respond — but this happens outside the model itself.
The model’s underlying parameters do not change.
What Real-Time Learning Would Require (and Does Not Happen)
Real-time learning would mean:
- The model’s internal weights are updated during or after a single interaction
- That update persists for future users or future sessions
- The behaviour of the system measurably changes as a result
This does not occur in deployed large language models.
Updating model weights requires:
- Large training pipelines
- Controlled datasets
- Validation and safety checks
- Offline retraining
It cannot happen “on the fly” during a chat.
Why the Confusion Exists
The confusion usually comes from three things being mistaken for one another:
- Tool use
The model queries something external. - Context retention
Information is held temporarily within the current session. - Model training
Parameters are updated offline at scale.
Only the third is learning.
The first two are not.
What Live Data Access Is Not
Live data access does not mean:
- The model remembers what it sees
- The model updates itself
- The model becomes smarter over time
- The model stores user conversations for learning by default
Any training that occurs happens later, selectively, and under separate processes — not during live use.
Why This Matters
Misunderstanding this distinction fuels claims that:
- AI systems “absorb everything you say”
- Private conversations instantly improve the model
- Live access equals surveillance or memory
These claims collapse inference, tools, and training into one vague idea of “learning” — and that idea is inaccurate.
Where To Go Next
For a related Explanation, see What “Model Memory” Actually Means in AI
For a related Rumour, see OpenAI Secretly Trained GPT-5 on Users’ Private ChatGPT Conversations Without Permission