What training data really means — and why it matters
A clear explanation of what training data is, how AI models learn from it, and why misunderstandings about data lead to exaggerated claims about capability.
Artificial intelligence is often described as “trained on everything”, “trained on the whole internet”, or “trained on all human knowledge”. These phrases sound impressive and unsettling in equal measure — but they’re also misleading.
To understand what AI systems can and cannot do, we need a clear explanation of what training data actually is, how it is used, and why it shapes both the strengths and the limits of modern models.
No mystique. No hand-waving. Just the fundamentals.
What training data actually is
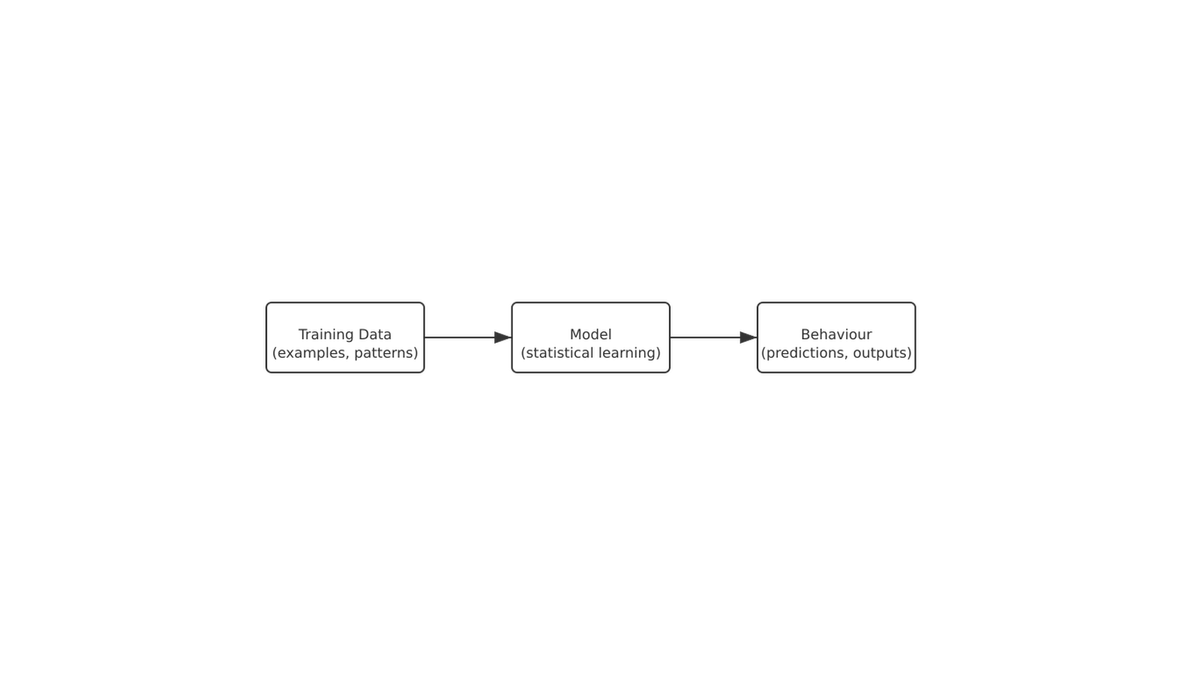
Training data is simply a large collection of examples the model uses to learn statistical patterns.
For a language model, the examples are sequences of text.
For a speech model, they are audio clips and transcripts.
For a vision model, they are images and captions.
The data does not contain understanding, reasoning, or meaning.
It contains patterns — and the model learns to predict what usually comes next.
That is the entire mechanism.
Training data is not “knowledge”
A model does not store facts the way a human remembers them.
If it appears to “know” that:
Paris is the capital of France,
it’s because millions of examples in its training data strongly associate the phrase “capital of France” with “Paris”. The model has no concept of countries, capitals, or geography. It has only the statistical residue of language.
This distinction matters.
A model’s behaviour is shaped by what it has seen, not by what it has understood.
Where training data comes from
Sources vary, but they typically include:
- publicly available webpages
- licensed datasets
- books (licensed or public domain)
- code repositories
- academic papers
- curated high-quality corpora
- synthetic data generated by other models
Contrary to myth, models are not trained on:
- private emails
- personal messages
- bank records
- internal company documents
Any training on non-public material requires explicit permission or licensing.
Why the composition of training data matters
The training data defines the model’s:
- strengths (where examples are abundant)
- weaknesses (where examples are sparse or absent)
- biases (from the patterns that occur most often)
- style (from how people tend to write)
- failure modes (from what the model has never seen)
Models are not omniscient. They are pattern-dependent.
This is why a model can write convincing legal text but then hallucinate a case that never existed: the patterns of legal language are strong, but the model cannot verify truth.
Training is not the same as memorisation
A common misconception is that models store their training data verbatim.
In reality:
- the training process compresses patterns,
- removes most specific details,
- and redistributes information across millions or even billions of parameters.
Memorisation can happen, especially in very large models and with rare or unique examples — but it is not the default behaviour.
Models remember patterns, not pages.
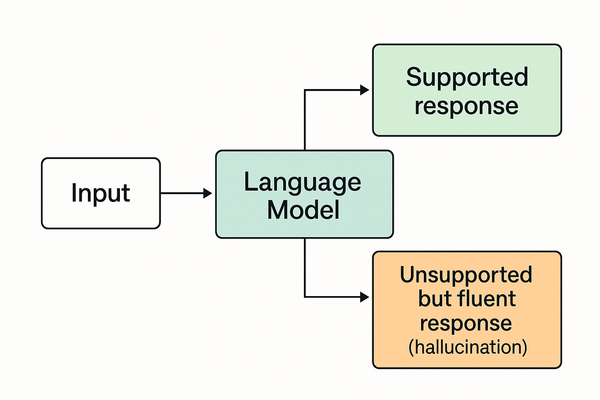
Why models hallucinate
Because a model predicts what is likely, not what is true.
When the question aligns well with its training distribution, the output is strong.
When it falls outside that distribution, the model must extrapolate — and this is where errors emerge.
The model is not “lying”.
It is producing its best guess based on statistical echoes of what it has seen.
This is why understanding training data is essential to understanding model behaviour.
The role of synthetic data
As models grow, companies increasingly rely on synthetic training data — examples generated by other models.
This raises new questions:
- Does synthetic data amplify existing biases?
- Does it reinforce a model’s own errors?
- Does it lead to “model collapse”, where output diversity shrinks over time?
These questions are active areas of research, and deeply relevant to how future systems will behave.
Why training data transparency matters
Without clarity about training sources, it becomes difficult to assess:
- the model’s true capabilities
- its blind spots
- its risk profile
- its potential for harmful bias
- its compliance with copyright frameworks
Transparency isn’t just an ethical issue — it’s a practical one.
Users need to understand what a model has and has not learned from.
Why this matters for AI Rumour Watch
Understanding training data allows readers to:
- distinguish realistic capability claims from implausible ones
- spot when a rumour relies on impossible or absent data sources
- evaluate “superintelligence” headlines with grounded scepticism
- recognise when hype conflates statistical prediction with understanding
- make sense of claims about reasoning, consciousness, and autonomy
Clear thinking about training data is the foundation for clear thinking about AI itself.
Where to go next
- For a concise explanation of model behaviour, see How Chatbots Actually Work Behind the Scenes.
- For examples of how training myths drive capability rumours, see our posts on Claude 3.5’s “10× tokens” claim and Llama 4’s alleged AGI-level training.