What “Alignment” Actually Means in AI — And What It Doesn’t
A clear explanation of what AI “alignment” really means, how it works, and why it is often misunderstood as a guarantee of safety or moral behaviour.
Introduction
“Alignment” is one of the most frequently used — and most misunderstood — terms in AI. Claims range from “models are already aligned with human values” to “alignment will solve all safety problems.” In practice, alignment is narrower, more technical, and far less settled than the public discourse suggests.
What people think alignment is
Common misconceptions include:
- “Alignment means the AI behaves ethically.”
- “Aligned models won’t produce harmful content.”
- “Alignment is a solved problem — just add safety filters.”
- “Alignment guarantees models won’t deceive or manipulate.”
These interpretations oversimplify a complex research area and imply levels of control that current systems do not possess.
What alignment actually refers to
In technical terms, alignment is about ensuring that:
- Models do what their designers intend
- Outputs reflect desired behaviours under specific conditions
- Systems avoid certain failure modes (e.g., dangerous instructions, disallowed content)
- Reinforcement learning and fine-tuning shape model behaviour toward human-preferred responses
Alignment does not mean complete safety, moral correctness, or human-like judgement.
It is an ongoing process, not a final state.
How alignment is implemented today
Modern alignment approaches include:
- RLHF (Reinforcement Learning from Human Feedback) — training models to prefer certain responses
- RLAIF (RL from AI Feedback) — scalable feedback loops from strong evaluator models
- Safety policy conditioning — using prompts or system messages to restrict behaviour
- Data filtering — removing toxic, illegal, or high-risk content from training sources
- Red-teaming — adversarial testing to uncover weaknesses
These techniques improve behaviour but remain imperfect and uneven across contexts.
Why alignment isn't the same as safety
Safety refers to:
- preventing dangerous or harmful outcomes
- ensuring reliable behaviour in real-world deployment
- mitigating systemic risks (misuse, bias, misinformation, etc.)
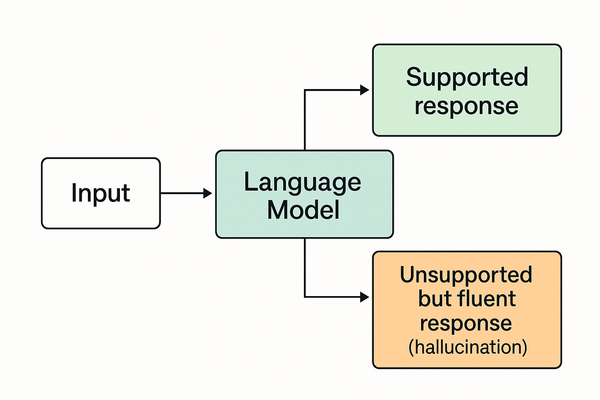
A model can be “aligned” (in the RLHF sense) while still:
- hallucinating
- producing harmful instructions when coaxed
- failing under distribution shift
- showing inconsistent moral reasoning
- being misused by malicious actors
Alignment ≠ morality
Alignment ≠ robustness
Alignment ≠ guarantee of harmless outputs
Common misuses of the term
The word “alignment” is often stretched to mean:
- General safety
- Ethical behaviour
- Truthfulness
- Control
- AGI containment
- Anthropomorphic traits like loyalty or obedience
These uses distort the technical meaning and inflate public expectations.
Why the term matter
Clarity around alignment helps:
- Reduce hype
- Improve AI governance discussions
- Distinguish capabilities from behaviour shaping
- Prevent false assurances about model safety
- Highlight gaps where research is incomplete
Better definitions support better public understanding — and more realistic debates.
Where to go next
For a related Explanation, see: What Training Data Really Means — And Why It Matters
For Rumours shaped by this misconception, see: OpenAI Secretly Trained GPT on Private Data