What AI Hallucinations Actually Are — and What They Aren’t
What AI “hallucinations” actually are — and what they aren’t. This explanation clarifies why models confidently produce false outputs, how prediction differs from knowledge, and why hallucinations are a structural limitation rather than a bug or deception.
What people usually mean by “hallucinations”
When people say an AI is “hallucinating,” they usually mean one thing:
the model produced information that sounds plausible but is false.
That might be:
- a made-up citation
- an invented technical detail
- a confident answer to a question it does not actually have evidence for
The key issue is not tone or creativity.
It’s false certainty.
What hallucinations actually are
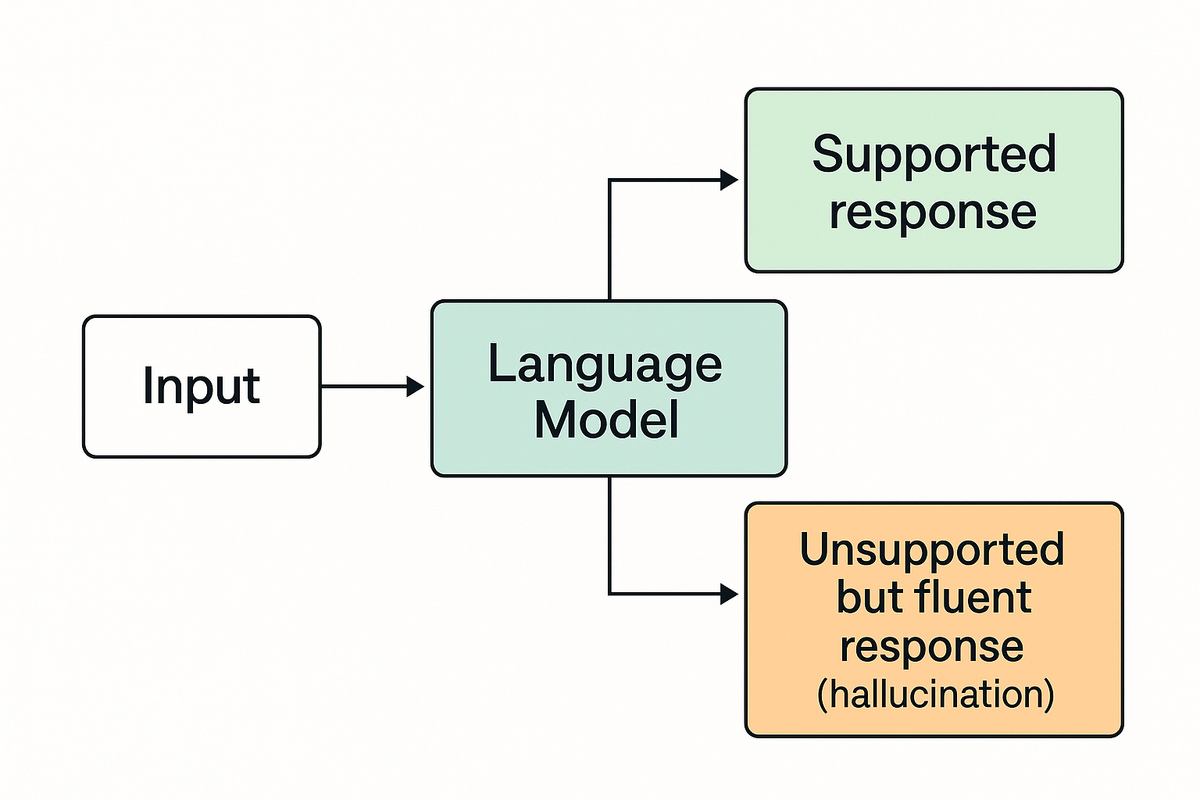
At a technical level, hallucinations are the result of probabilistic language generation.
A language model does not retrieve facts.
It predicts the most likely next token based on:
- training patterns
- the current prompt
- the surrounding context
If the model lacks reliable signal, it does not stop.
It continues predicting anyway.
That continuation — when unsupported by verifiable information — is what we call a hallucination.
Importantly:
- the model is not “imagining”
- it is not accessing hidden memories
- it is not lying
It is doing exactly what it was trained to do.
What hallucinations are not
Hallucinations are often misunderstood as evidence of deeper or darker behaviour. They are not:
- Hidden memory recall
The model is not pulling secret facts from storage. - Private data leakage
Hallucinations do not indicate access to user conversations or logs. - Independent reasoning
The model is not “thinking for itself” in the human sense. - System intent or deception
There is no goal to mislead. Only continuation.
The confidence comes from language fluency — not from knowledge.
Why hallucinations feel convincing
Hallucinations are especially persuasive because:
- language models are optimized for coherence, not truth
- fluent structure signals authority to human readers
- the model does not internally distinguish “known” from “unknown” unless explicitly constrained
In other words, the model sounds confident because confidence is a linguistic pattern — not a belief state.
Why this keeps getting misinterpreted
Hallucinations are frequently framed as:
- proof of secret memory
- evidence of hidden training data
- signs of emergent awareness
These interpretations confuse:
- output behaviour with internal architecture
- product experience with model capability
- confidence with knowledge
The result is a persistent myth that hallucinations reveal something the system “knows but shouldn’t.”
They don’t.
Why hallucinations are a structural limitation
Unless a model is:
- tightly grounded
- externally verified
- or explicitly constrained to say “I don’t know”
It will always hallucinate in edge cases.
This is not a temporary flaw.
It is a consequence of how generative models work.
Why this matters
Misunderstanding hallucinations leads directly to other false beliefs, including:
- that AI systems secretly store everything users type
- that models remember past conversations across sessions
- that confident answers imply factual access
Those claims build on the same misunderstanding — and collapse under inspection.