Did OpenAI Train on Everyone’s Private Data?
An investigation into what AI companies actually train on, what they don’t, and why the rumour of “they used my private data” continues to spread.
A Breakdown of What’s Actually True
Many people assume AI companies secretly absorb private emails, chats, documents, and personal cloud storage into training datasets. The rumour persists because modern AI models sound like they know more than they should, and because tech companies often communicate in ways that obscure rather than clarify.
This investigation explains what training data really consists of, why the misconception exists, and where the genuine points of concern actually lie.
What People Think AI Was Trained On
A common belief is that large AI models were fed personal messages, private cloud files, or confidential data scraped directly from individual accounts. This is not what happens — but the rumour thrives because the industry never communicated boundaries clearly.
- Many users assume “smart = spying.”
- AI models produce fluent language that feels personal.
- Misleading headlines (“AI read everything you’ve ever typed”) contributed to confusion.
- Companies were slow to explain how internet-scale datasets differ from private sources.
Together, these factors create the perfect environment for misunderstanding.
What AI Models Are Actually Trained On
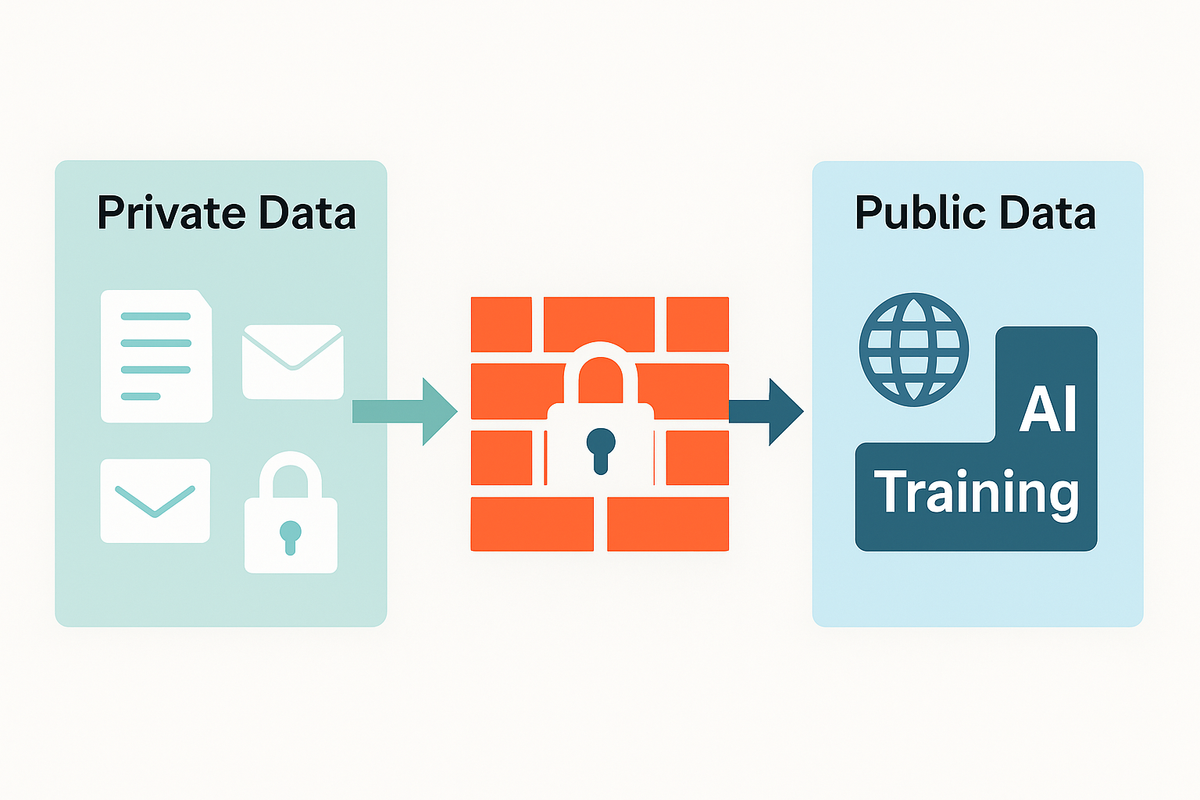
Training data comes from large-scale public or commercially-licensed corpora, not from private messages or personal cloud accounts. There are still genuine debates about what counts as “public,” but private user data is not ingested.
- Public web pages, crawls, forums, and documentation.
- Digitised books and academic datasets (mixed legality).
- Licensed proprietary sources from publishers or aggregators.
- Synthetic data generated from earlier models.
The reality is messy, but it is not “your personal emails were used.”
Why This Rumour Refuses to Die
The mechanics of LLM behaviour make the models appear to know private things. Combined with vague corporate explanations, this feeds the misconception.
- Personalised-sounding responses create an illusion of memory.
- LLM confidence gives an impression of insider knowledge.
- Overlapping public data (e.g., social media posts) feels personal even when not private.
- Tech-company messaging often prioritised excitement over clarity.
The rumour persists because the experience feels personal — not because the data is.
Timing Tells Its Own Story
Several key moments amplified the rumour of “private data training,” even though the underlying practices didn’t change.
- The release of ChatGPT coincided with headlines about data scraping lawsuits.
- New privacy policies were misreported, causing panic.
- Companies retroactively clarified wording long after public suspicion formed.
- Regulatory announcements often arrived after models were shipped, not before.
The sequence made everything look more suspicious than it was.
Where Contamination Could Happen
Although private accounts aren’t used in training, ambiguity exists around grey-area datasets and data provenance. This is where realism is needed.
AI companies may accidentally include:
- Public data that was never meant to be publicly accessible.
- Copyrighted content without licence (being litigated).
- Data scraped from forums where users didn’t expect industrial-scale harvesting.
In short: contamination risk exists — but not in the form the rumour assumes.
Regulatory Implications
This area is now heavily scrutinised by governments and courts. The focus is shifting from “Was private data used?” to “What counts as lawful, fair, and consent-based training?”
- New rules will define acceptable data sources at scale.
- Transparency requirements will force clearer dataset disclosure.
- Companies will need to defend why certain sources qualify as “public.”
Regulation won’t solve the rumour — but it will solve the ambiguity that fuels it.
Conclusion
The widespread belief that OpenAI trained on private emails, chats, and documents is not supported by the technical or operational reality of how large datasets are built. Yet the rumour persists because models feel intrusive, marketing language blurred boundaries, and companies communicated poorly.
The truth is more mundane and more complicated: models learn from vast public and licensed sources, not your private cloud. But the line between “public” and “consented” is thin — and that ambiguity, not espionage, is the real issue.
- For background on related mechanics or concepts, see What “Model Memory” Actually Means in AI
For Rumours influenced by this misconception, see Rumour AI Companies Secretly Train on Your Private Messages